
Una de las tareas más importantes de un SEO es la auditoría SEO , con este trabajo lo que buscamos es descubrir y solucionar errores que puedan afectar al posicionamiento web de nuestra página o a su funcionamiento en general, enlaces rotos, redirecciones que no funcionan, directivas de etiquetas mal aplicadas, incluso contenido duplicado son algunos de los problemas que pueden perjudicar nuestro crecimiento.
La herramienta que analizaremos hoy 🐸 nos permite realizar completas auditorías a nuestra web (o las de los clientes) y ahorrarnos horas de trabajo, ya que como veremos más adelante podemos automatizar todo el proceso, desde el análisis a la generación de los informes, incluso cruzar datos con otras herramientas como aHrefs, Google Analytics, Moz, Majestic… por lo que su potencial es enorme.
Gracias por tu colaboración, lo prometido es deuda… 🤝
Si registras tu dominio con Namecheap, podrás conseguir increíbles descuentos, un .com desde sólo 5,57€ / año.
La clave para descomprimir el archivo comprimido es: 25807
[DESCARGAR LISTA DE 25.807 DOMINIOS LIBRES CON AUTORIDAD DE NEGOCIOS] [/sociallocker]Screaming frog es una aplicación de escritorio (tenemos que ejecutarla en nuestro ordenador) que va a funcionar como un crawler, es decir, recorrerá todo el sitio web recogiendo datos, muchos muchos datos, que luego nosotros podemos interpretar y tomar decisiones, es cierto que a primera vista la interfaz de Screaming no la hace muy amigable, tiene decenas de pestañas y opciones de configuración (que aprenderemos hoy!) y eso puede desbordarnos un poco, hoy aprenderemos a exprimir Screaming Frog y a no tenerle miedo!

✅ Realiza auditorías SEO On Page completas a webs
✅ Integración con otras herramientas (aHrefs, Moz, …)
✅ Automatización de tareas
✅ Scrapeo de contenido
✅ Versatilidad
Tabla de contenidos
Encontrar enlaces rotos
Monitorizar backlinks creados
Detectar páginas sin títulos, descripciones …
Encontrar páginas no indexadas
Analizar la distribución de autoridad entre páginas internas
Validar datos estructurados
Encontrar páginas huérfanas …
¿Qué hace Screaming Frog?
Como hemos mencionado más arriba Screaming Frog SEO Spider (su nombre y apellidos) es un programa que podemos ejecutar en nuestro PC y se encarga de recorrer todas las páginas / URLs de un sitio web (puede ser nuestro o no) y recoger información como H1, etiquetas, enlaces de la página (entrantes / salientes), número de palabras, imágenes, archivos de estilo (CSS), peso, etc…
No te preocupes, las principales opciones de Screaming Frog (puede hacer muchas más combinando las existentes o personalizándolas) las he escondido a propósito para que no te abrumen sólo con ver el listado, lo realmente interesante es conocer qué tareas puede hacer Screaming Frog por nosotros, más allá de conocer sus detalles técnicos, que iremos desgranando.
Instalar Screaming Frog
Cuidado porque si pasas Screaming Frog por una web de cientos de miles de URLs puede estar muchas horas procesando toda la información.
💡 Lo más adecuado es sino tienes un equipo de sobremesa y no quieres dejar el portátil encendido todo el día es que contrates un VPS con Windows para ejecutar este tipo de programas como Scrapebox, Screaming Frog… que pueden estar funcionando horas y horas, además de agotar la RAM de tu ordenador para otras tareas.
Ojo! Que puedes correrlo en tu portátil sin problemas, pero si lo acabas usando tanto como yo estará prácticamente todo el día funcionando… además, como veremos más adelante tiene muchas opciones de automatización que permiten que el programa ejecute tareas de forma «autónoma» por lo que es conveniente que esté en un equipo 24 / 7.
Si ya dispones de una máquina para correr el programa, en tu propio equipo o en un VPS, lo primero que debes hacer es descargarlo desde la página de los desarrolladores.
1 Descarga la última versión para tu sistema operativo desde la página web de Screaming Frog.
La versión de Windows, que es la que yo uso, ocupa unos 250 MB por lo que si tu conexión es de fibra tardará muy poco en descargarse, guárdala en una carpeta temporal porque después de instalarlo podrás eliminar el archivo de instalación.
Versiones disponibles para descargar:



2 Ejecuta la instalación

Doble click en el ejecutable que descargaste para iniciar la instalación, si tienes Windows 10 igual te aparece el típico mensaje de Control de Cuentas de Usuario para permitir la ejecución del programa, le confirmas SI y continúa la instalación.
* Al ser un programa que se ejecuta sobre el entorno Java puede ser que si tienes instalada una versión antigua del mismo te obligue a actualizar, hay programas (antiguos) que requieren una versión concreta de Java por lo que al instalarlo no marques eliminar la versión antigua o puede ser que dejes algún programa sin funcionar en tu equipo.
Ahora debes elegir entre dos opciones Default o Custom, la única diferencia entre las dos, es que la opción Custom te permite seleccionar la ruta donde se ubicaran los archivos del programa, que por defecto es «C:\Program Files (x86)\Screaming Frog SEO Spider«, si no necesitas cambiar la ruta (te recomienda instalarla en C y más si tienes un disco duro SSD) pulsa en el botón Install.

Ahora sólo queda esperar unos segundos a que el programa termine de instalarse en nuestro equipo, aparecerá el mensaje completado encima de una ventana rollo Matrix, después podrás pulsar en Close (cerrar).
Si vas al escritorio ya deberías ver un acceso directo a Screaming Frog, y sino, busca en Inicio > Programas, desde ahí puedes sacar un enlace para tenerlo a mano.
Conoce Screaming Frog
La curva de aprendizaje de Screaming Frog no es sencilla, tiene muchas opciones, requiere de una configuración inicial pero sobre todo requiere que has de saber muy bien lo que estás haciendo, digamos que no es una herramienta para todos los públicos.
Herramientas como Website Auditor únicamente requieren que introduzcas la URL de la web a auditar y ella se encarga del resto y nos muestra un informe más o menos avanzado de información que ha extraído de la web, pero no es tan potente ni tan versátil como Screaming Frog, además en caso de sitios muy grandes se agradece la cantidad de personalización de Screaming Frog, analizando y extrayendo sólo aquello que necesitamos.
Configuración inicial
 Antes de lanzarnos a la aventura de auditar un sitio con Screaming Frog, has de tener en cuenta algunos aspectos, esta herramienta no es como Ahrefs que le pides los backlinks de la Wikipedia y te lo muestra en segundos (porque ya los tiene rastreados), nosotros vamos a rastrear desde cero todo aquello que queramos, tendremos datos actualizados y en tiempo real, a cambio debemos esperar todo el tiempo que tarde en procesarlos.
Antes de lanzarnos a la aventura de auditar un sitio con Screaming Frog, has de tener en cuenta algunos aspectos, esta herramienta no es como Ahrefs que le pides los backlinks de la Wikipedia y te lo muestra en segundos (porque ya los tiene rastreados), nosotros vamos a rastrear desde cero todo aquello que queramos, tendremos datos actualizados y en tiempo real, a cambio debemos esperar todo el tiempo que tarde en procesarlos.
El tamaño de la web con la que vamos a trabajar es clave, si es una web de 5000 URLs nos da igual no revisar la configuración de rastreo, pero si son 4.000.000 de URLs aplicar bien la configuración o no puede suponer un ahorro de mucho tiempo de trabajo.
Por ejemplo no rastrear las imágenes, los enlaces externos… toda esas opciones podemos personalizar desde Configuración, si evitas rastrear cosas que no necesitas en webs grandes puedes ahorrar mucho tiempo de trabajo.
Para acceder a esta configuración inicial vamos a desplazarnos al menú principal, Configuration -> Spider
💡 Una vez que tengamos configurado todo a nuestro gusto podemos guardar estas opciones para no tener que volver a revisar las pestañas una a una.
 |
Desde esta sección podemos marcar qué tipo de fichero o de enlace queremos que la araña siga o no, además podemos elegir la opción de seguir y/o almacenar.
Imágenes, ficheros de estilos CSS, JavaScripts, SWF (Flash), sino vamos a trabajar específicamente con ellos es muy útil desmarcarlos para que el trabajo se realice mucho más rápido y necesitando menos recursos. También podemos configurar el trabajo de rastreo teniendo en cuenta el tipo de enlace, internos / externos, canonicals, paginaciones, hreflang, AMP o MetaRefresh. Y como comportamiento podemos elegir si queremos que el crawler trabaje en varias carpetas, por ej: seodelnorte.com/blog/ o no rastree lo que está fuera de esta, si queremos que rastree todos lo subdominios, seguir / no seguir enlaces nofollow. Sitemaps. Podemos indicar al programa que siga los sitemaps que le añadimos de forma manual, que los busque en el robots.txt o simplemente que los ignore. |
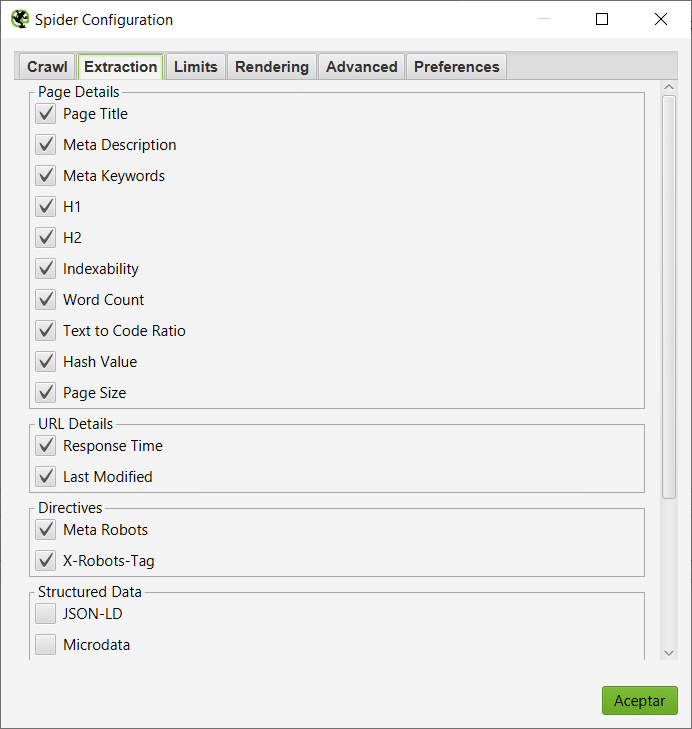 |
En la sección Extraction, tenemos todas las opciones disponibles que la araña va a extraer y almacenar de cada página, muchas veces no nos serán necesarios todos, yo normalmente suelo quitar Page Size, Hash Value, Word Count, Text to Code Ratio, pero depende de cada proyecto y de la tarea que estés realizando.
Muy útil dejar marcada en la opción Directives, la opción Meta Robots, X-Robots-Tag para saber cuál tenemos configurada en cada página y no se nos cuele un Noindex, en una página importante por error. Si usas datos estructurados en la página, puedes comprobar si se están implementando de forma correcta o no. Si quieres trabajar con el renderizado de HTML o ver la página tal como la interpreta Google podrás marcar las casillas de HTML. |
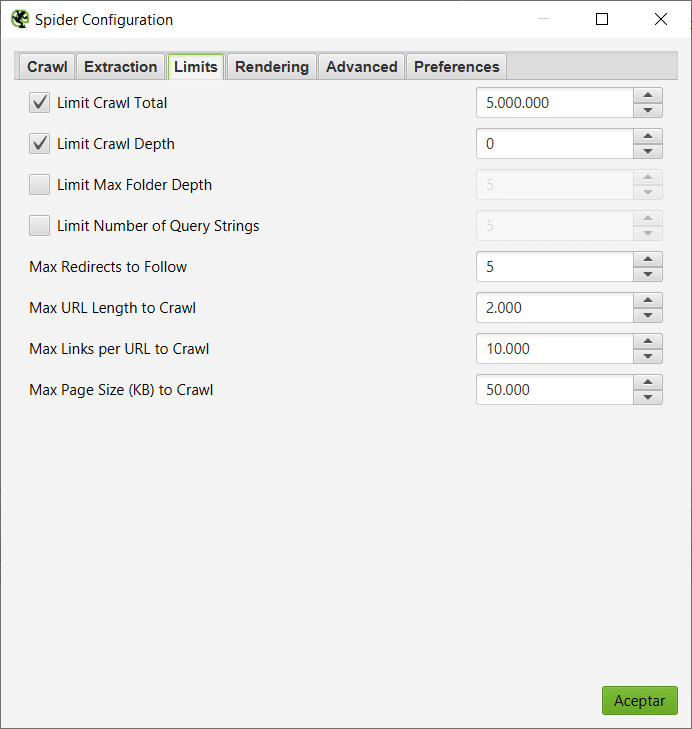 |
Este software está pensado para recorrer y analizar webs grandes, pero podemos limitar su trabajo y por tanto los recursos que vamos a consumir desde la sección de Limits.
Podemos limitar el número total de URLs que analizaremos, la profundidad total que el crawler puede trabajar (los enlaces que se encuentran a un click de la home, los que se encuentran a dos clicks, etc…), profundidad de carpetas o número de cadenas de la consulta. También podemos limitar:
|
 |
En las opciones avanzadas podemos permitir las cookies al rastrear un sitio, seguir redirecciones, canonicals, hacer caso a los noindex (y no rastrear esas páginas)… y varias opciones más.
Lo importante de esta sección es marcar la pestaña «Pause on High Memory Usage» que lo que hará será pausar el trabajo en el caso de que se esté usando mucha memoria para poder guardarlo y continuar, porque si se excediera el uso de memoria disponible del ordenador podría colgarse el programa y perder todos los resultados almacenados hasta el momento. Esta opción de la que ya te puedes aprovechar tú a mi me costó algún tiempo, muchos cabezazos y horas de trabajo perdidas hasta que le supe sacar partido. |
 |
La última sección de la configuración de Screaming Frog nos permite ajustar el máximo de algunos valores de los que recibiremos una alerta en el informe si se sobrepasan, por ejemplo:
|
La interfaz de Screaming Frog
Si te parece fea ahora es que no probaste las primeras versiones… en cualquier caso, puede ser abrumador por la cantidad de pestañas, columnas, menús que encontramos al abrir por primera vez el programa, pero piensa que son muchos los datos que podemos manejar y encontrar un equilibrio entre tener todo accesible y hacerlo visualmente ligero es difícil.
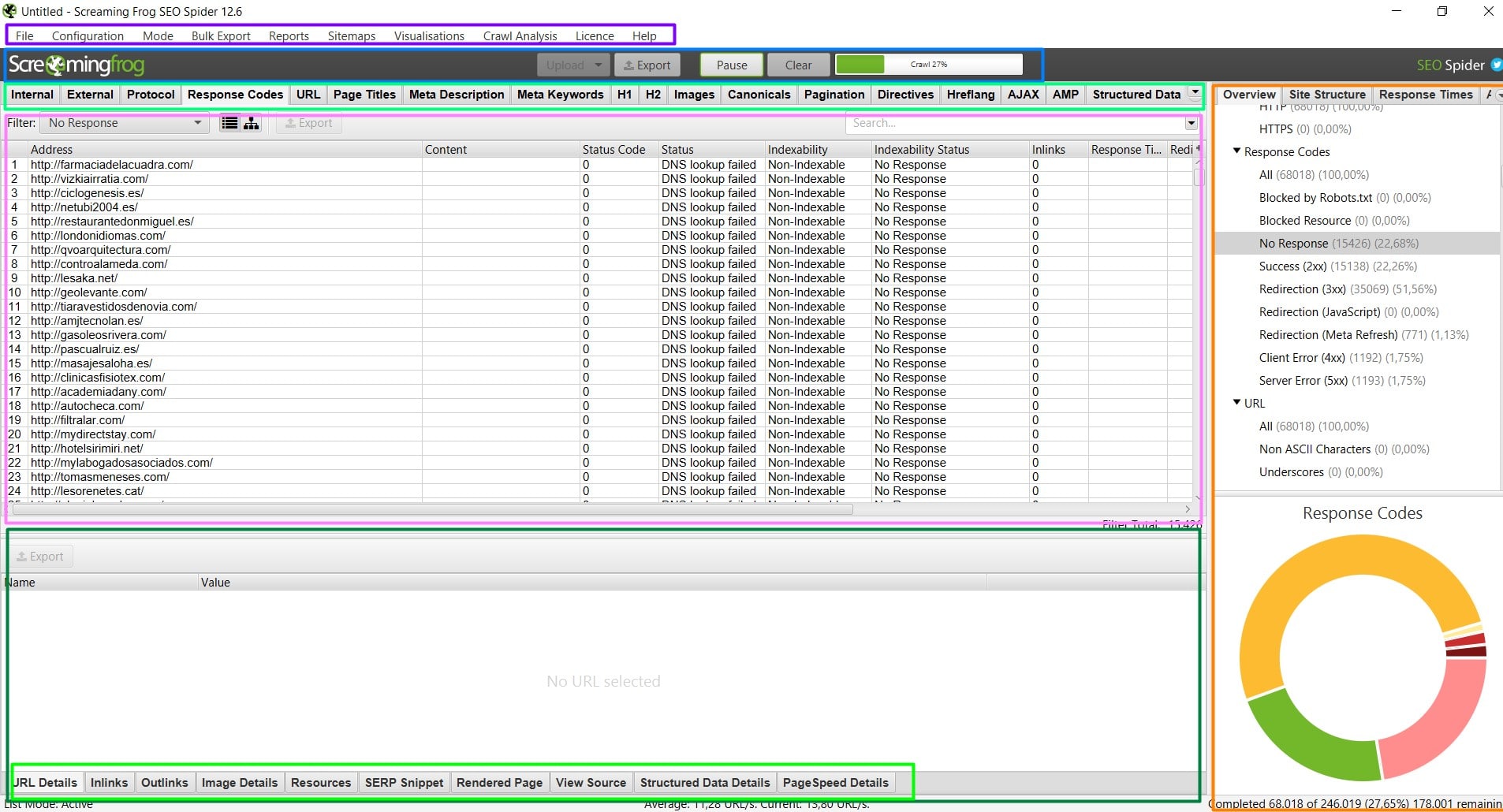
Es el menú desde el que podemos manejar todas las opciones del programa, no sólo del proyecto con el que estemos trabajando en ese momento.
File
Desde esta sección podremos guardar o cargar proyectos con los que estemos trabajando, cerrar el programa.
Pero además encontramos dos de las opciones más potentes con las que contamos en Screaming Frog, Scheduling que nos permite programar (con cierto grado de configuración) en el tiempo análisis de distintas webs sin tener que preocuparnos, muy útil por ejemplo para almacenar en una carpeta de un cliente un análisis semanal o mensual que nos sirva como historial al que recurrir si algo falla.
Y Configuration, desde donde podemos guardar o recuperar toda la configuración de Screaming Frog, muy útil para hacer distintas configuraciones centradas en diferentes aspectos y simplemente recurrir a ellas al iniciar un nuevo análisis sin tener que revisar la configuración general.
Configuration
- Spider – La sección más importante, desde aquí podemos configurar cómo se comporta el crawler con la web, qué elementos queremos que recoja o que ignore, qué límite de profundidad, en qué carpetas, etc…
- Robots.txt – Cómo queremos que Screaming trate el archivo robots.txt si lo encuentra en un sitio, que lo ignore o que lo cumpla. En la pestaña Custom podemos añadir nosotros mismos las directivas de robots.txt (en el caso de que no tengamos uno en la web) que queremos que se sigan para ese sitio, excluyendo urls o directorios, etc.
- URL Rewriting – Nos permite renombrar y eliminar parámetros indeseados de las URLs que procesamos.
- CDNs – Si usas un CDN (Content Delivery Network) como Akamai, CloudFlare, etc. Puedes indicarlo en este apartado, así sus dominios serán tomados como internos, los enlaces y carpetas de los mismos como parte de tu proyecto.
- Include – Una muy potente opción que nos permite gracias al uso de Regex, limitar qué rutas queremos que el crawler trabaje, por ejemplo, en nuestro caso, si queremos únicamente analizar la sección del blog (seodelnorte.com/blog), deberemos introducir en include «https://www.seodelnorte.com/blog/.*». (Podemos introducir tantas URLs o expresiones regulares como queramos)
- Exclude – Al contrario y siguiendo el ejemplo anterior, si queremos analizar todo el sitio menos la sección del blog, tendríamos que introducir la misma línea (https://www.seodelnorte.com/blog/.*) en esta sección de exclude, que nos permite excluir determinadas secciones, rutas o URLs del trabajo del crawler.
- Speed – Desde aquí puedes aumentar la velocidad del crawler, te aconsejo hacerlo mediante URLs, aumentar los hilos de procesamiento de forma significativa podría hacer muchas cientos de peticiones al sitio web, sobrecargarlo e incluso dejarlo inactivo. Una velocidad más lenta requerirá además menos memoria para procesar el trabajo.
- User-Agent – Podemos cambiar el User Agent, con el que el programa trabajará, muy útil por si algún sitio tiene bloqueado determinado user agent, puedes usar los más comunes o personalizar uno propio.
- HTTP Header – En esta sección podemos personalizar por completo la cabecera HTTP
- Custom (Search, Extraction) – Uno de los apartados más potentes de Screaming Frog ya que nos permite buscar cualquier cosa en el código de la web y/o scrapear contenido de nuestra web o de otras webs.
- User Interfaz – Personalizar el interfaz del programa
- API Access (Google Analytics, Google Search Console, Page Speed Insights, Majestic, aHrefs, Moz) – Desde aquí podemos configurar el acceso a la API de las herramientas soportadas por Screaming Frog para poder utilizar sus datos en los informes generados con Screaming
- Authentication – Si tienes un sitio en desarrollo o simplemente si necesitas autenticarte para ver todo el contenido (por ejemplo una comunidad, un foro…) desde aquí puedes añadir los datos necesarios para que use el crawler.
- System (Memory, Storage, Proxy, Embedded Browser) – Configura las opciones de sistema del programa, memoria que puede ocupar (dependiendo de la que tengas instalada en el equipo), carpeta de almacenamiento, proxy o si quieres usar el navegador integrado en el programa por defecto o no.
Mode
- Spider – En este modo el programa recorrerá todas las URLs del sitio web que vaya encontrando siguiendo los enlaces.
- List – De esta forma podemos subir una lista de URLs que serán las que se analicen.
- SERP – Podemos comprobar si nuestros títulos y descripciones se ajustan a las SERPs.
Bulk Export
Esta función está pensada para exportar los datos de la herramienta y trabajar con otras herramientas.
- All Inlinks – Exporta a un hoja de cálculo todos los enlaces entrantes
- All Outlinks – Exporta a una hoja de cálculo todos los enlaces salientes
- Queued URLs – Exporta a una hoja de cálculo las URLs en espera
- All Anchor Text – Exporta a una hoja de cálculo todos los anchor text de los enlaces
- All Images – Exporta a una hoja de cálculo todas las rutas de las imágenes del sitio
- Screenshots – Permite exportar los Screenshots (si el renderizado con Javascript está activo)
- All Page Source – Exporta a una hoja de cálculo todos los orígenes de datos
- External Links – Exporta a una hoja de cálculo todos los enlaces externos
- Response Codes – Exporta a una hoja de cálculo todos los códigos de respuesta de las URLs analizadas
- Directives – Exporta a una hoja de cálculo las URLs con las directivas que le indiquemos (noindex, nofollow, noarchive…)
- Canonicals – Exporta a una hoja de cálculo todas las URLs con etiquetas canonicals
- AMP – Exporta a una hoja de cálculo datos de las páginas AMP (enlaces entrantes, códigos de respuesta, etc…)
- Structured Data – Exporta a una hoja de cálculo todos los datos estructurado
- Images – Exporta a una hoja de cálculo las rutas de las imágenes del sitio que no tengan ALT o que sobrepasen determinado peso
- Sitemaps – Podemos exportar los sitemaps generados
- Custom Search – Exporta a una hoja de cálculo los datos que hemos obtenido con una custom search
- Custom Extraction – Exporta a una hoja de cálculo los datos que hemos extraído con custom extraction
Reports
- Crawl Overview – Un resumen de todo el rastreo que ha procesado es por defecto la primera pantalla que vemos al terminar el trabajo el crawler.
- Redirects – Podremos ver todas las redirecciones que se están produciendo en el sitio
- Canonicals – Un informe de todos los canonicals del sitio (también podemos sacar únicamente de aquellas que no están indexadas)
- Pagination – Páginas de paginación que no están funcionando, testeamos la implementación de las etiquetas rel=»next», rel=»prev»
- Hreflang – Si estás trabajando con sitios internacionales deberás controlar la implementación de las etiquetas Hreflang
- Insecure Content – Nos sacará un listado de todas las URL «no seguras», es decir, aquellas que no usan HTTPS
- SERP Summary – Nos permite ajustar nuestros títulos y descripciones al ancho requerido por los resultados en la SERPs
- Orphan Pages – (requerida API Analytics) Nos mostrará un listado de las páginas huérfanas encontradas (aquellas que no tienen ningún enlace entrante)
- Structured Data – Nos permite validar los datos estructurados que hayamos implementado en nuestro sitio
- Page Speed – Nos permite aplicar los filtros de la herramienta de Page Speed a nuestro sitio, es decir, los consejos de mejora de WPO podemos aplicarlos y ver qué elementos se pueden mejorar
Sitemaps
Desde aquí podemos crear de una forma muy sencilla un sitemap para nuestro sitio (o un sitemap de imágenes) y podemos configurar algunas opciones sobre qué páginas meter, cambiar la prioridad, incluir imágenes, etc…
Visualisations
La herramienta más gráfica de Screaming Frog, nos permite ver de forma visual la estructura de un sitio web, son muy útiles a la hora de hacernos una idea de la estructura real de un sitio web, aunque no aportan más datos de los que ya puedes ver en el informe normal. Hay dos tipos de visualizaciones Rastreo y Directorio, en la primera podemos ver cómo el crawler ha ido rastreando el sitio y en el segundo podemos ver cómo sería el directorio del sitio web, es decir, en carpetas.
Yo suelo utilizarlos cuando empiezo con un nuevo proyecto para entender su estructura y cómo se reparten las URLs y autoridad.
Crawl Analysis
Podemos realizar un análisis de factores SEO que afectan al sitio web con el que estemos trabajando, métricas que se calculan y no pueden recogerse del sitio.
El crawl analysis es muy útil para conocer si el interlinking está bien planteado o debemos de introducir cambios para distribuir la autoridad o link juice de la página correctamente.
Link Score – Esta es una métrica propia de Screaming Frog que nos ayuda a hacernos una idea del valor de cada enlace
Pagination – Errores en paginaciones
Hreflang – Ausencia de la etiqueta o mal configuradas
AMP – Código de respuesta correcto y etiqueta bien implementada
Sitemaps – Comprueba que existen los sitemaps, que las URLs incluidas responden bien, etc…
Analytics – (necesita que conectes la API de Google Analytics) Localización de páginas huérfanas
Search Console – (necesita que conectes la API de Google Search Console) Localización de páginas huérfanas
License
Desde aquí podrás introducir tu licencia o comprar una, sino la tienes aún te aseguro que pocas herramientas hay en el mercado tan útiles por el precio que ofrecen, lo único negativo que tendrás que desembolsar el pago anual de golpe.
Help
Guía de usuario (muy útil pero sólo en inglés), versión del programa, memoria libre y usada, etc…
Introducción datosDesde esta barra podemos indicar la URL con la que vamos a trabajar, pegar URLs, subir un fichero con URLs, etc… dependiendo del modo que elijamos.
Menú superiorAquí encontraremos las pestañas (pueden variar dependiendo de si añadimos herramientas externas gracias a las API) en las que vamos a encontrar clasificada la información que Screaming nos muestra y puedes cerrarlas pulsando con el botón derecho sobre ellas.
Listado de URLsAquí encontramos el listado de URLs analizadas con los datos agrupados en columnas, desde configuración puedes personalizar qué columnas quieres ver y cuáles no.
Barra lateralPodemos ampliar la información o acceder de forma directa a la información contenida en las pestañas así como a gráficas y resúmenes más visuales de la información.
Ampliar información de URLCuando tenemos una URL seleccionada, desde este menú tenemos la posibilidad de ampliar la información referente a la misma, como enlaces entrantes, screenshot, datos estructurados, enlaces salientes…
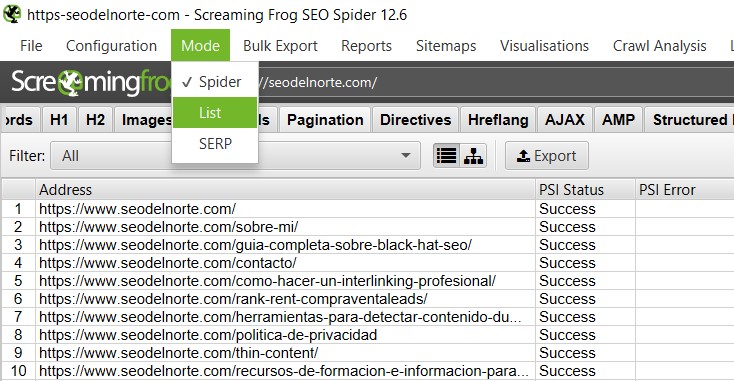
Estos modos nos permiten modificar la forma en la que Screaming Frog va a procesar los datos.
- Spider – será el propio programa el encargado en recorrer toda la web como un crawler, siguiendo los enlaces (internos y externos, podemos modificarlo) que se vaya encontrando
- List – podemos añadirle un listado de URLs (manualmente o desde un archivo), de forma que sólo procese esas URLs y no siga los enlaces
- SERPs – Nos permite procesar las URLs tal como aparecen en las páginas de resultado de los buscadores, para poder optimizar el título, descripción, etc…
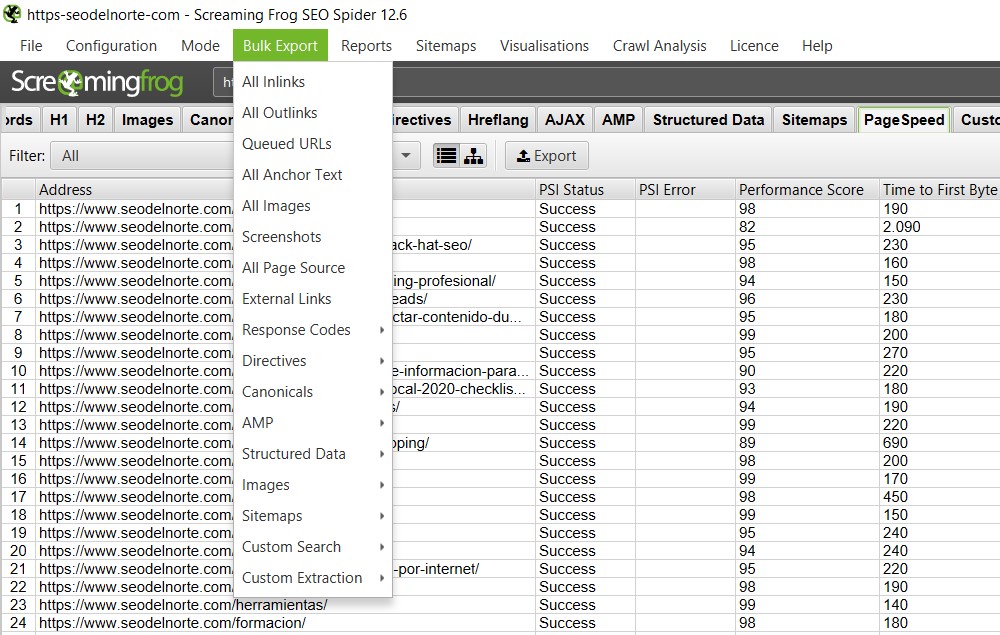
Tipos de informes que podemos exportar:
- All Inlinks – Enlaces entrantes
- All Outlinks – Enlaces salientes
- Queued URLs – URLs en espera
- All Anchor Text – Anchor text de los enlaces
- All Images -Imágenes del sitio
- Screenshots – Screenshots del site
- All Page Source -Orígenes de datos
- External Links – Enlaces externos
- Response Codes – Códigos de respuesta de las URLs
- Directives – Directivas
- Canonicals – Canonicals
- AMP – Páginas AMP
- Structured Data – Datos estructurado
- Images – Imágenes
- Sitemaps – Sitemaps del sitio
- Custom Search – Búsqueda personalizada
- Custom Extraction – Extracción de datos personalizado
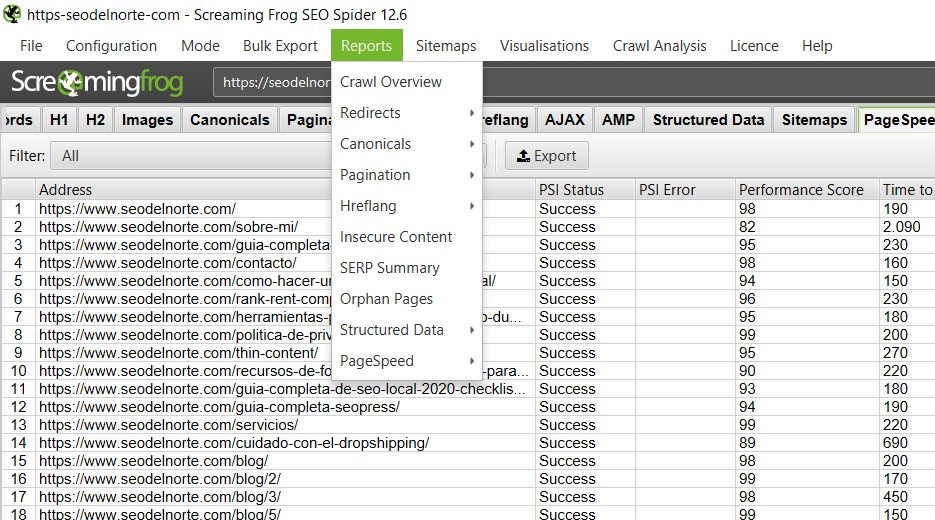
Reportes que podemos generar:
- Crawl Overview
- Redirects
- Canonicals, Pagination
- Hreflang
- Insecure Content
- SERP Summary
- Orphan Pages
- Structured Data
- Page Speed

Desde aquí podrás generar los sitemaps del sitio web en caso de que no los tenga.
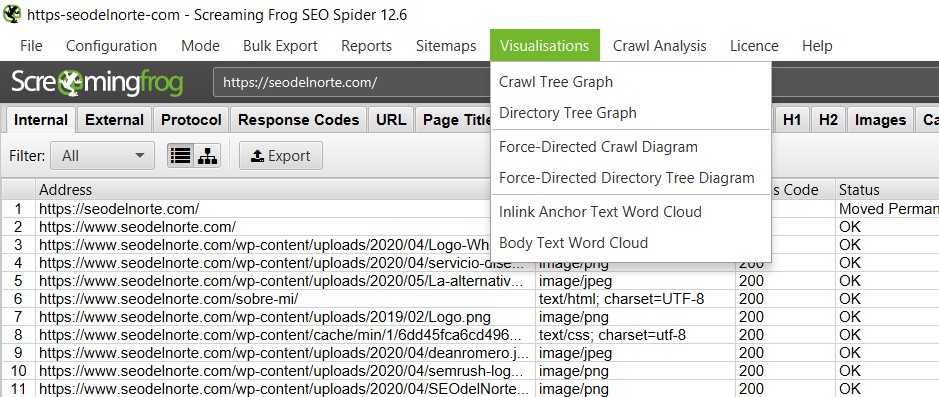
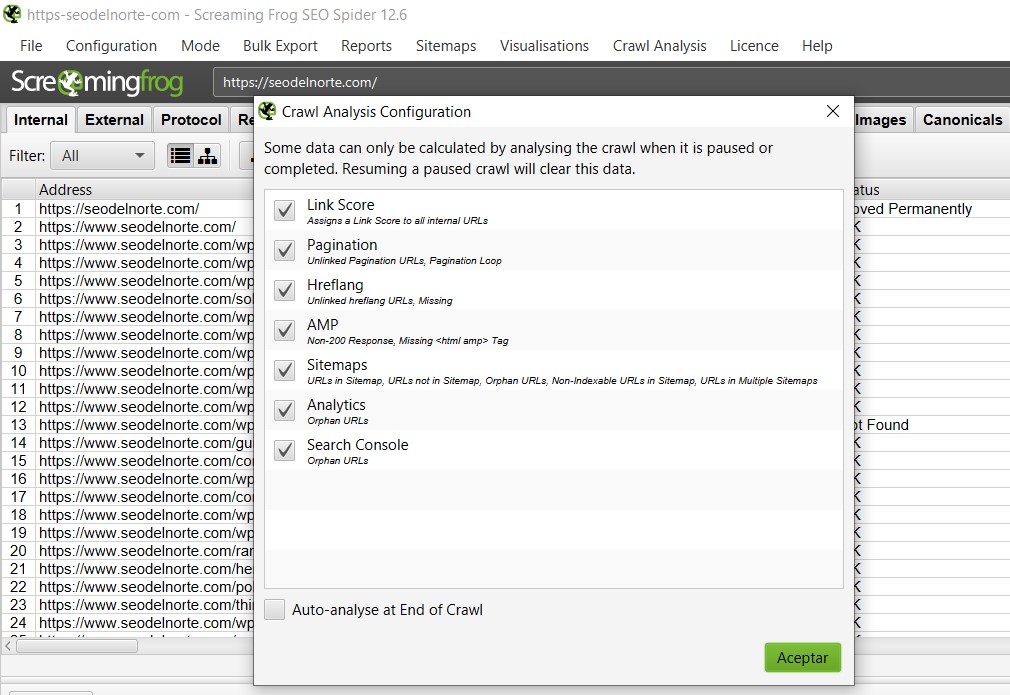
🔬 Analizando una web
Vale, ya sabemos todo lo que Screaming Frog puede hacer por nosotros, pero ahora vamos a ponerlo en práctica, vamos a tomar como referencia este blog, y vamos a ver con un ejercicio práctico cómo realizo yo una sencilla auditoría SEO On Page con Screaming Frog, para encontrar los problemas más graves en una web. Ojo, con la versatilidad de este programa habrá mil formas distintas y mejores de hacerlo, pero eso ya depende de los datos en los que le guste a cada uno centrarse o lo que requiera el proyecto en cuestión.
Lo primero que haremos será añadir la URL del blog, desde el Modo de Araña, pues lo que queremos es que el crawler recorra todos los enlaces del sitio (recuerda que desde configuración puedes seleccionar si quieres que siga los enlaces externos, hasta qué profundidad, imágenes, CSS o JavaScript, etc…).

Desde la pantalla principal tendremos acceso a un montón de información vital para la salud del sitio web, yo suelo empezar por revisar:
- Código de estado de las URLs, revisar aquellas que dan error 404, o 50x…
- Revisar que no están marcadas como «Non-indexable» URLs que sean de valor para los usuario
Abajo a la derecha podrás comprobar las páginas totales de nuestro sitio, puedes comparar ese resultado con el devuelto por el comando «site:seodelnorte.com» para comparar las páginas que tiene indexadas Google con las que realmente tiene nuestro sitio web y descartar posibles problemas de indexación.
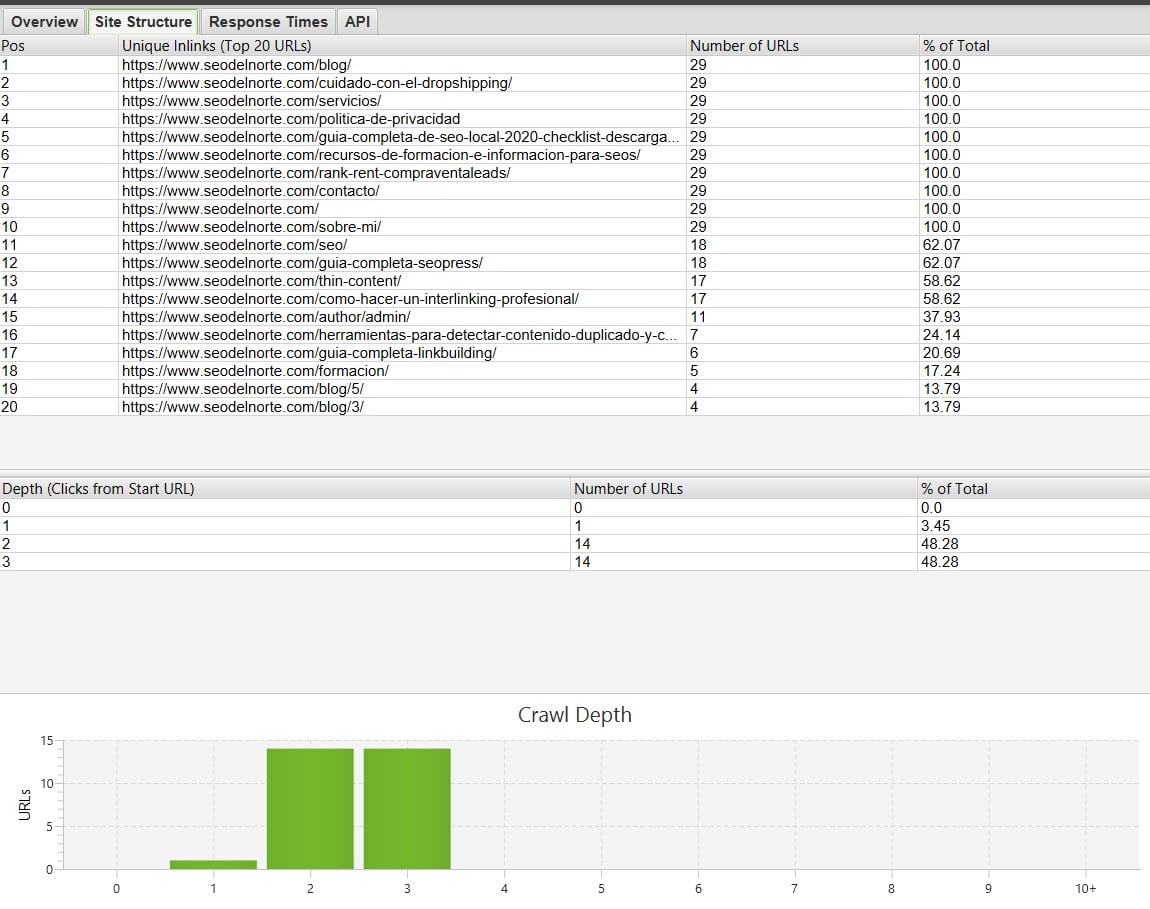
En la barra lateral de la derecha tendrás acceso a información sobre la estructura del sitio, te permite hacerte no sólo una idea del tamaño y estructura del sitio web, sino además conocer a qué profundidad se encuentran sus URLs (puede acarrear problemas de indexación).
En nuestro caso, vemos que el 100% de las URLs se encuentran en los tres primeros niveles de profundidad, más allá de ellos podría dificultar el rastreo de los crawlers (aunque no siempre es así, claro!).

Ahora vamos a repasar todos los H1 (H2, H3…) de cada página, para ver si tenemos la keyword incluida en el título (siempre que tenga sentido), sino tenemos la etiqueta H1 vacía o repetida, etc.

Un vistazo a el listado de todas las imágenes de la web nos servirá para ver si hay alguna que tenga demasiado peso y pueda ralentizar la carga de la web.

Vamos a ver si las etiquetas canonicals están bien implementadas, sino las conoces son las etiquetas que dicen a Google que la página de autoridad es otra y no la que está accediendo, se usa por ejemplo si hay varios artículos de una temática relacionada para no canibalizar contenidos, o en el caso de paginaciones, etc…

En este último paso, aunque no es algo básico, ya que como verás incluye mucha más información de la que vas a poder procesar, el informe de Page Speed (tendrás que añadir una KEY para poder usar la API) es muy útil para conocer aquellas URLs que están teniendo problemas de carga y en concreto qué lo está provocando.

💡 Otras tareas útiles que puedes hacer con Screaming Frog
Llevo muchos años leyendo sobre esta herramienta en la red y algo que siempre me había dejado con mal sabor de boca y espero no hacerlo con esta guía, son los textos que se limitan a explicar la herramienta y sus funcionalidades sin aportar ideas sobre formas de trabajar con ella que como habrás intuido a estas alturas son casi infinitas.
Así que aquí va mi aportación con 5 ideas sobre tareas que puedes realizar de forma automática con Screaming Frog mejorando así tu productividad y consiguiendo resultados que tendrías que pagar en otras herramientas y no sabías que podías hacer con esta.
1 Conseguir dominios expirados para web Rank&Rent
Si ya has visto mi guía para crear y monetizar una web de venta de leads, y estás pensando en ponerte manos a la obra, encontrar un dominio con autoridad y expirado puede hacer que tu proyecto empiece unos peldaños más arriba para empezar a generar ingresos, un dominio expirado es un dominio con autoridad pero que han dejado caducar, es decir, está libre para registrar.
Hay muchas formas de encontrar dominios de este tipo, incluso servicios en línea como ExpiredDomains donde puedes acceder de forma gratuita a listados con miles de dominios caducados con autoridad, el problema es que hay mucha gente con acceso a esa información y es difícil conseguirlos y que son dominios generales y nosotros buscamos dominios específicos de empresas o relacionados con temática de negocios locales.
Vamos a ver cómo conseguir dominios caducados con autoridad de una temática o ciudad que elijamos con Screaming Frog, ya que hemos pagado la licencia vamos a exprimirla al máximo.
1 Vamos a tener que conseguir un listado de dominios para revisar, podemos ir a la web de Datos.gob.es, que ofrecen muchos datos sobre actividades empresariales en España, si buscamos empresas, el primer resultado que nos aparece es una BD de empresas en Alcobendas, para el ejemplo nos sirve… 🙂La información se muestra en muchos formatos, para este ejercicio vamos a elegir el .csv que nos permite trabajar mejor con los datos.

Descargamos el fichero que contiene todas las empresas, si abres el .csv y ves un montón de datos amontonados ve a la sección Datos > Organizar por columnas.
2 Ahora vamos a meter ese listado de URLs a Screaming Frog, a primera vista sólo podemos introducir una URL para escanear, tienes que cambiar el modo entre los tres existentes: Spider (por defecto), List y SERP.
Una vez seleccionado el modo «List» podremos añadir las urls de forma manual pegándolas directamente en una caja de texto o si son varias miles de ellas te recomiendo hacerlo subiendo un archivo de texto.

Una vez que hayamos añadido las URLs el programa va a empezar a procesarlas de forma automática y lo que más nos interesa a recoger los los códigos de respuesta que más tarde nos van a decir si un dominio está libre o no.
Aparecerán muchos códigos, los que nos interesa son los que están marcados como DNS Lookup Failed, puedes verlos marcando la opción «No response» dentro de la pestaña Response Codes en la barra lateral derecha, o simplemente ordenando la lista por códigos, aunque si es muy larga se puede hacer tedioso.

3 Ya tenemos el listado de dominios «libres» (algunos no lo estarán), lo que debemos hacer ahora es pasar un segundo filtro, haremos una búsqueda en algún registrador de dominios como por ej, DonDominio (que tiene búsqueda masiva), Dynadot, etc…

El paso siguiente es revisar la lista, seleccionar los que más se adecuan al nicho que quieres montar de web local, o simplemente pasarlos por alguna herramienta como el Análisis de Lotes de aHrefs que te va a sacar de forma masiva los datos más interesantes de los dominios como autoridad, enlaces entrantes, keywords posicionadas, etc… y de un vistazo puedes seleccionar los más interesantes.
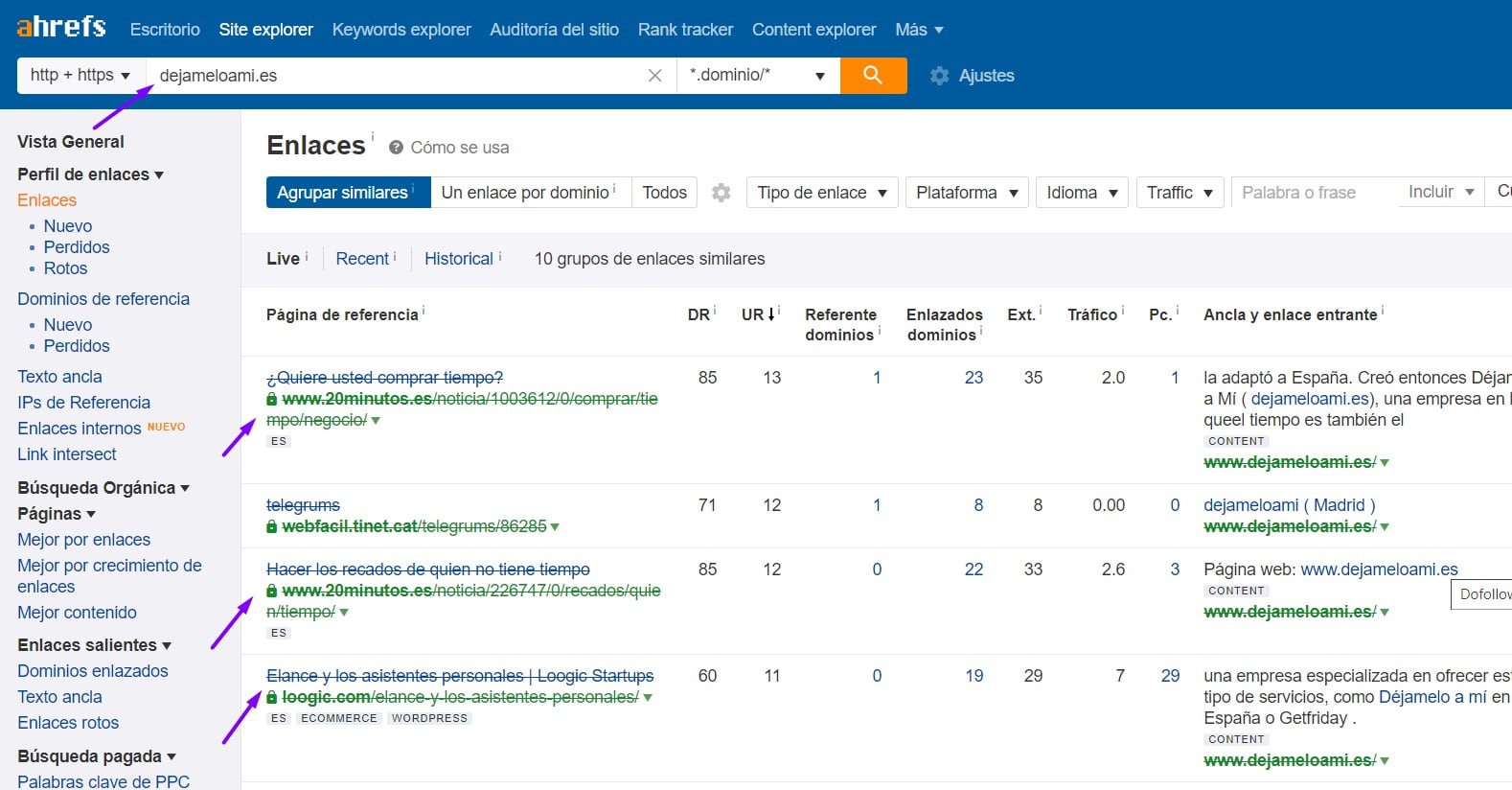
En mi caso me fijé en el dominio dejameloami.es, simplemente porque es el que apareció el último en la lista no hice este ejercicio para encontrar dominios, le hice una consulta rápida en Ahrefs y aunque tiene muy pocos backlinks, 2 son de noticias que hablan sobre esa web (no en comentarios) en 20minutos.es y otro de Loogic.com (un blog con autoridad).
Gracias por tu colaboración, lo prometido es deuda… 🤝
La clave para descomprimir el archivo comprimido es: 25807
[DESCARGAR LISTA DE 25.807 DOMINIOS LIBRES CON AUTORIDAD DE NEGOCIOS][/sociallocker]
2 Migrar una web
Las migraciones web es uno de los procesos más traumáticos que como consultor/a SEO vas a tener que enfrentarte, o al menos a mi me pasa, y la presión va directamente proporcional al volumen de tráfico del proyecto, todos sabemos la teoría de que Google asa la mayoría de autoridad con una redirección 301, pero, en una migración, hay muchas cosas que pueden salir mal.
Por suerte, el programa de la ranita una vez más nos puede ayudar, no a llevar a cabo la migración porque eso debemos hacerlo nosotros, pero sí a preparar unos logs o informes previos a la migración y los mismos de forma posterior para conocer con exactitud qué diferencias se pueden haber generado en URLs, etiquetas cambiadas, enlaces rotos, etc …
Tipos de migración, en el mejor de los casos si la migración sólo es un cambio de dominio, pero no supone cambios de URLs, estructura web ni nada similar, nuestro trabajo consistirá básicamente en cambiar el dominio antiguo por el nuevo en la web y comprobar que todas las nuevas URLs realizan la llamada al nuevo dominio, para que cuando el viejo deje de apuntar a las DNS de nuestro servidor no dejen de funcionar.
En el peor, te tocará enfrentarte a un cambio de estructura y URLs, por lo que tendrás que elaborar un archivo .htaccess con todas las redirecciones 301 de a URL antigua a la URL nueva, también aquí Screaming Frog puede ayudarte.
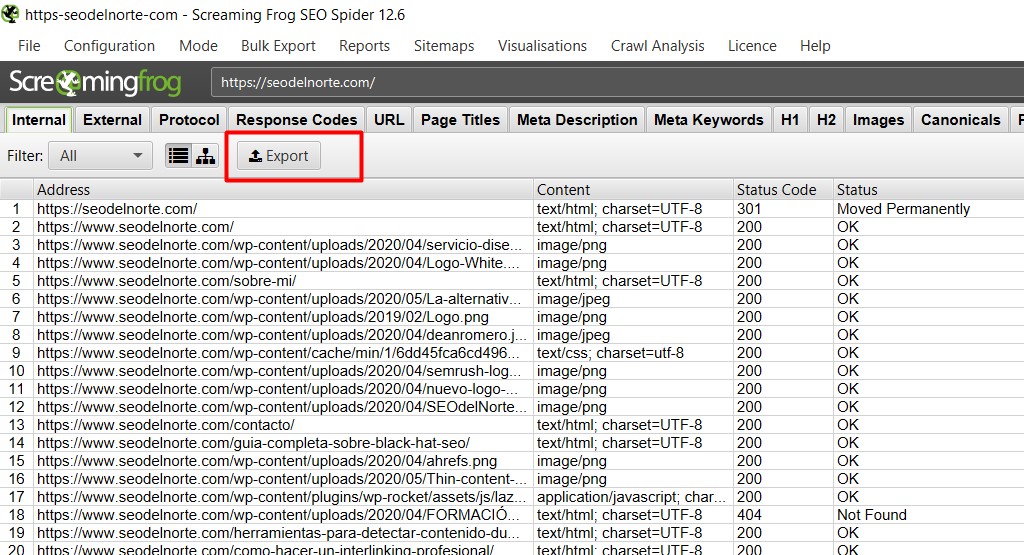
Paso 1.- El primer paso que debes dar es, antes de realizar nada de la migración, hacer un análisis del sitio actual y exportar todos los elementos que lo componen (URLs, imágenes, etiquetas, redirecciones, etc…), de esta forma tenemos una referencia a la que acudir para ver cómo estaba el sitio previo a la migración.
Para eso una vez finalizado el análisis, desde la pestaña de Internal, asegúrate de seleccionar ALL (no sólo imágenes, o html, o css… etc) puedes pulsar en el botón Export, te generará un archivo con todas las URLs (de todos los tipos) del sitio.
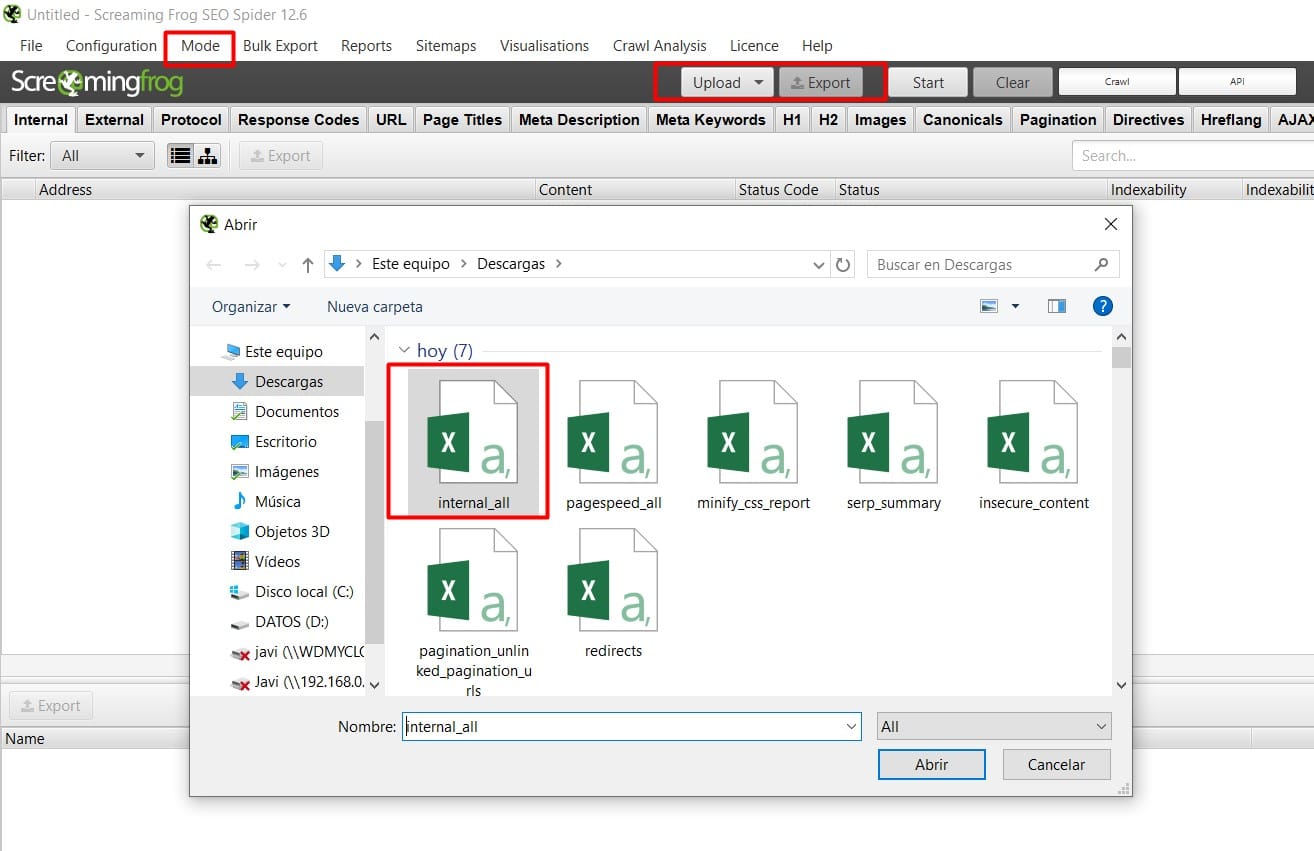
Paso 2.- Una vez que hayas realizado la migración, siempre puedes recurrir y ver el análisis previo a la migración desde la sección Mode -> List, e importando el archivo que exportamos en el paso 1.
3 Comprobar que las etiquetas hreflang están bien implementadas
Hace poco leí un tuit de Sergio Simarro (a quién te recomiendo seguir) que opinaba que Google muy pronto dejaría de utilizar la etiqueta hreflang para sitios internacionales por todo el trabajo que les llevaba procesar esta etiqueta en los sitios y no le falta razón, si a nosotros los SEOs se nos hace cuesta arriba organizarla en un sólo sitio, no me quiero imaginar tener que interpretarla como hace Google.
Por suerte, Screaming Frog también nos puede ayudar en esta tarea, si tienes un sitio en varios idiomas orientado a distintos países o mercados, con Screaming puedes revisar que tienes bien implementado hreflang, asegurándote que cada usuario puede ver la versión de la web que corresponde a su país o idioma.
Antes de empezar con el análisis, debemos asegurarnos de tener marcada la pestaña Hreflang en la configuración inicial.
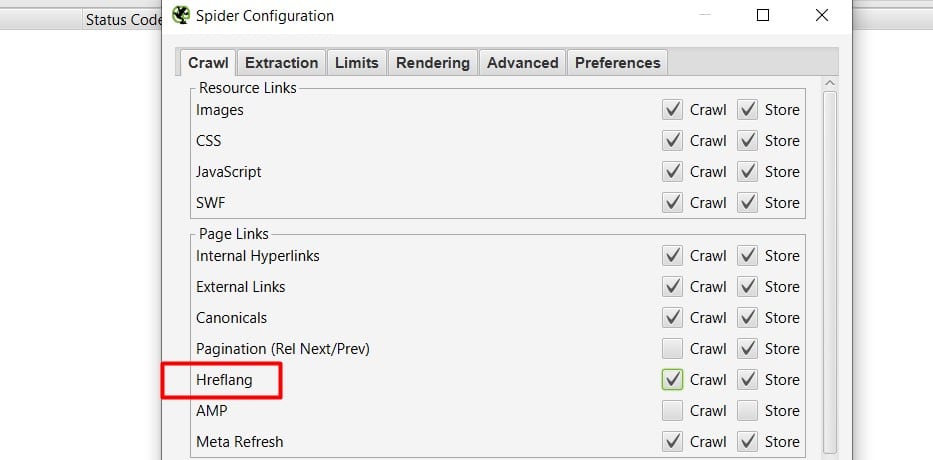
Vamos a poner como ejemplo Tripadvisor, se me ocurren pocas páginas que tengan versiones en más idiomas que este enorme portal de turismo, ¿no? Pues manos a la obra, para el ejemplo no he dejado que complete el análisis, porque me podría tirar horas, además de la primera página que encuentre sacará todas las versiones de idiomas, pero si vas a analizar tu web, sí te recomiendo que recorra todas las URLs.
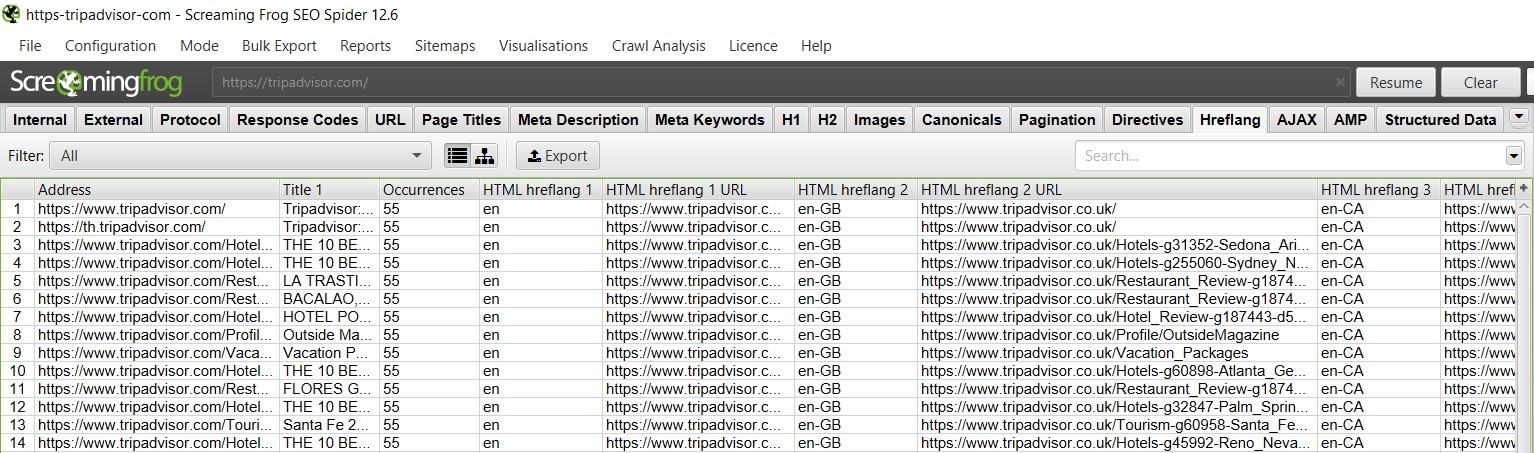
Como ves, muestra la información en columnas, la primera Ocurrences, nos indica el número de etiquetas Hreflang en esa URL y en las columnas posteriores irá mostrando el código de hreflang y la URL donde apunta.
4 Extrayendo emails de usuarios por temática
Como vimos en la sección de Interfaz, Screaming Frog tiene una potente herramienta para buscar cualquier contenido en la web que queramos, podemos además añadir tantos campos como queramos (hasta 100) lo que nos permite personalizar aún más esa búsqueda.
¿Qué podemos hacer? Pues desde buscar etiquetas sin poner en nuestra web, sacar precios de productos, títulos de los artículos de la competencia… hasta extraer cientos o miles de emails de potenciales clientes.
Imagina que acabas de abrir una web de pesca, el tráfico orgánico tardará en llegar y no tienes demasiado presupuesto para gastar en campañas SEM, vamos a buscar emails de personas a las que le gusta la pesca, ¿cómo? Muy sencillo, puedes ir por ejemplo a un foro de pesca y buscar «@gmail.com», lo que nos sacará correos de personas que hayan publicado en esa página.
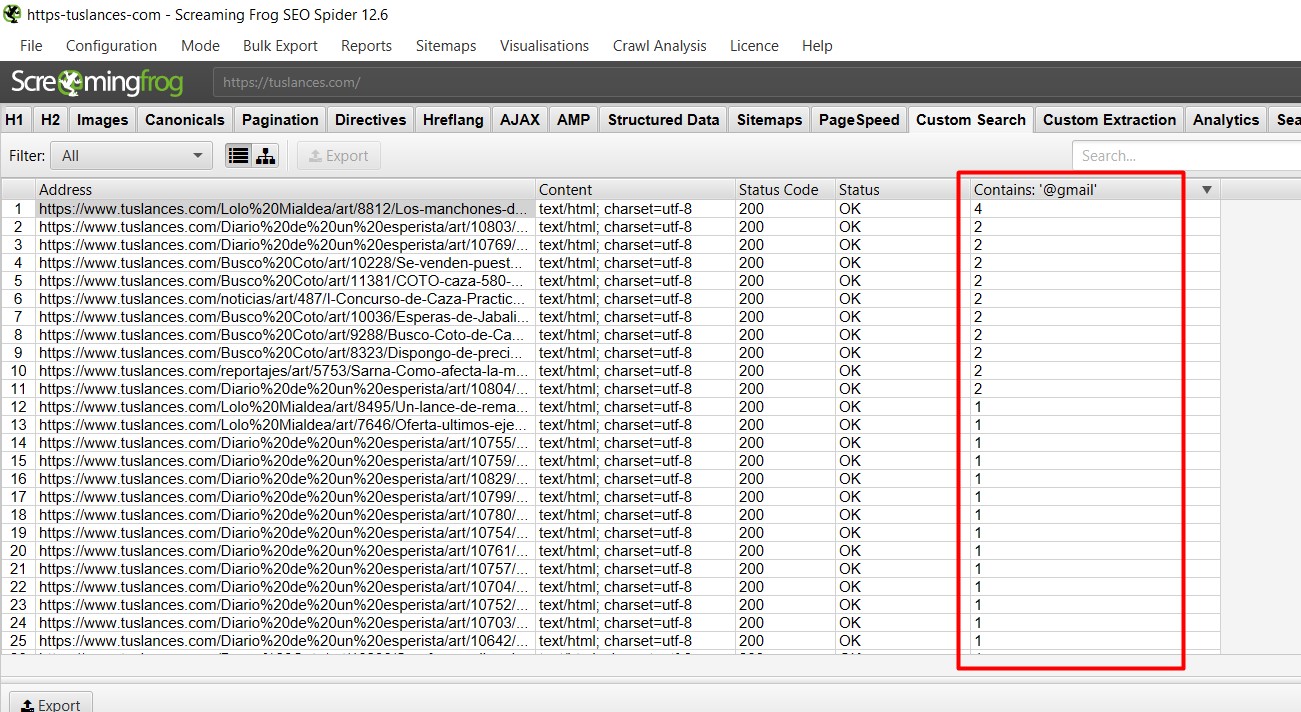
Ahora ya tenemos cientos o miles de URLs donde aparecen correos de «gente interesada en la pesca», podríamos usar el Custom Extraction para sacar ese contenido, como hicimos en un apartado anterior, pero lo más sencillo es simplemente que te instales un addon para Chrome como Email Extractor, que precisamente lo que hace es recoger emails de las URL que visitemos y listo.
5 Encontrar páginas huérfanas
Las páginas huérfanas, son aquellas que dentro de nuestro sitio web no reciben ningún enlace, por tanto, Google no podrá indexar porque no tiene forma de llegar a ellas, y no recibirán tráfico.
El principal problema que nos pueden acarrear este tipo de páginas, es que, tratándose de una URL que queramos posicionar, al no poder ser crawleada ni indexada esa página no recibirá nunca tráfico, aunque lo normal es que se trate de páginas «olvidadas», landings que usamos de forma puntual y nos olvidamos de eliminar, páginas de ejemplo de estilos del tema que estemos usando, pero también pueden ser páginas creadas por algún virus, etc.
Hay varias formas de detectar este tipo de páginas, podemos revisar los logs del servidor (existe una herramienta especializada desarrollada por la misma agencia que Screaming Frog, Log File Analyser), donde seguramente se haga alguna mención a esa página o podemos una vez más recurrir a Screaming Frog, que tiene una función para encontrar este tipo de páginas (tendrás que configurar la API de Google Analytics y Google Search Console), sólo asegúrate que el Modo es araña (Mode Spider).

Hasta ahora encontrar páginas huérfanas requería de tediosos procesos de cruzar datos con herramientas como Analytics o GSC, ahora con Screaming Frog la podemos sacar de forma sencilla
📚 Referencias
No puedo hacer un artículo de Screaming Frog sin mencionar a Mjcachon, quien se puede considerar la «embajadora» de Screaming Frog en España, ha escrito mucho sobre la herramienta, ha dado muchas charlas y aporta mucha información interesante sobre la herramienta, su manejo y novedades, así que no dejes de pasar por su blog.




Uau! Vaya currada de artículo, me encantó lo bien que lo explicas, siempre he sido algo reticente a usar screamingfrog pero me diste alguna idea para lanzarme
Pingback: Errores más comunes de una estrategia de Posicionamiento SEO